
ԭ���⣺���������ٽ�����ѧ3���100��0��ѹ����ʯ��ɹ�
�ص���ʱ��10��18��18��00(����ʱ��19��01��00)��AlphaGo�ٴε������綥����ѧ��־��������Ȼ����
һ���ǰ��AlphaGo����2016��1��28�յ��ڵķ������£�Deepmind��˾�����ذ����ģ��������������ŷ��Χ��ھ�������˹����ܳ���
����5�£���3:0�ıȷ�Ӯ���й����ֿ½��AlphaGo�������ۣ���DeepMind��˾��û��ͣ���о��ĽŲ����ص���ʱ��10��18�գ�DeepMind�Ŷӹ�������ǿ��AlphaGo ������AlphaGo Zero�����Ķ����ؼ����ǡ���ѧ�ɲš������ң��Ǵ�һ�Ű�ֽ��ʼ�������ѧϰ���ڶ̶�3���ڣ���Ϊ�������֡�
�Ŷӳƣ�AlphaGo Zero��ˮƽ�Ѿ�����֮ǰ���а汾��AlphaGo���ڶ�����Ӯ�º�����������ʯ�ǰ�AlphaGoʱ��AlphaGo Zeroȡ����100:0��ѹ����ս����DeepMind�Ŷӽ�����AlphaGo Zero������о������ĵ���ʽ����������10��18�յġ���Ȼ����־�ϡ�
��AlphaGo�������ڴﵽ�ijɼ����������ڣ�AlphaGoZero��������ǿ�汾���������˺ܶࡣZero����˼���Ч�ʣ�����û��ʹ�õ��κ�����Χ�����ݣ���AlphaGo֮����DeepMind���ϴ�ʼ�˼�CEO����˹?������˹(DemisHassabis)˵�������գ�������Ҫ���������㷨ͻ�ƣ�ȥ����������ֽ��ȵ���ʵ�������⣬�絰�����۵�������²��ϡ��������ͨ��AlphaGo����������Щ������ȡ�ý�չ����ô������DZ���ƶ������������������Ի����ķ�ʽӰ�����ǵ������
����������֪ʶ���ƣ�ֻ��4��TPU
AlphaGo��ǰ�İ汾�����������������Χ��ר�ҵ����ף��Լ�ǿ��ѧϰ�ļලѧϰ����������ѵ����
��սʤ����Χ��ְҵ����֮ǰ���������˺ü����µ�ѵ�����������Ƕ�̨������48��TPU(�ȸ�רΪ������������������������з���оƬ)��
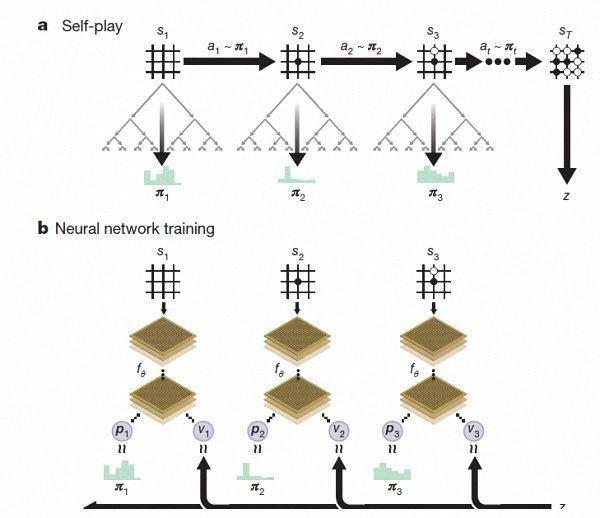
AlphaGoZero������������������������ʵ����������������ǣ���������Ҫ�������ݡ�Ҳ����˵����һ��ʼ��û�нӴ����������ס��з��Ŷ�ֻ��������������������������壬Ȼ��������Ҳ��ġ�ֵ��һ����ǣ�AlphaGoZero���dz�����̼����ֻ�õ���һ̨������4��TPU������ؽ�ʡ����Դ��
AlphaGo Zeroǿ��ѧϰ�µ����Ҷ��ġ�
���������ѵ����AlphaGoZero����˽�5�����̵����Ҳ��ĺ��Ѿ����Գ�Խ���࣬�������˴�ǰ���а汾��AlphaGo��DeepMind�Ŷ��ڹٷ������ϳƣ�Zero�ø��º��������������㷨���飬����ѵ���ؼ��ϵͳ�ı���һ��һ����ڽ��������Ҳ��ĵijɼ�ҲԽ��Խ�ã�ͬʱ��������Ҳ��ø�ȷ��
����Щ����ϸ��ǿ�ڴ�ǰ�汾��ԭ���ǣ����Dz����ܵ�����֪ʶ�����ƣ���������Χ����������ߵ�ѡ�֡���AlphaGo����ѧϰ���� AlphaGo�ŶӸ����˴���?ϯ����(Dave Sliver)˵��
�ݴ�����ϯ���߽��ܣ�AlphaGoZeroʹ���µ�ǿ��ѧϰ���������Լ��������ʦ��ϵͳһ��ʼ��������֪��ʲô��Χ�壬ֻ�Ǵӵ�һ�����翪ʼ��ͨ��������ǿ��������㷨�����������Ҷ��ġ�
�������Ҳ��ĵ����ӣ�����������������Ԥ����һ��������������Ӯ�ñ�������Ϊ�������ǣ�����ѵ�������룬DeepMind�Ŷӷ��֣�AlphaGoZero��������������Ϸ�����߳����²��ԣ�ΪΧ�����������Ϸ�������µļ��⡣
�����ߣ� �༭��������













